1.5 深入探究下高速串行通信常用的编码方式—8B/10B编码

内容简介
2024-01-29
内容梗概
高速串行通讯的应用愈发广泛,作为高速串行通讯重要内容的8B/10B编码也成了我们需要了解学习的内容,因为只有熟悉了8B/10B编码才能正确的理一些解高速串行传输机制,要不然会有好多问号徘徊在脑袋里,对此我深有感触。
要想真正理解8B/10B编码,就要知其所以然,这样是亘古不变的道理,为此我做了如下的内容安排:
第二章
8B/10B编码是什么?知道它是谁家的孩子,也就大体知道它是干什么的了
第三章
了解 8B/10B编码的作用,这也是它诞生的初衷,存在的意义。了解其作用,不仅是了解其作用,当我们紧抓其目的,也就能对其实现方式有了生层次的理解。
第四章
了解8B/10B编码是如何实现的以及背后的考量。
8B/10B编码是什么?
何为编码,编码就是信息从一种形式或格式转换为另一种形式的过程,例如用1表示3.3V,再例如我们熟知的ASCII码都是编码。8B/10B编码也是一种编码,我们可以简单的理解为用一个位宽10bit的数据来表示一个位宽为8bit数据的编码方式,但这种理解是直观的感受,更是粗浅的解释。
8B/10B编码其实不仅提供给我们将8bit数据用10bit表示这样一种编码方式,更重要的是为我们高速串行传输提供了一种链路控制方式,因为它是一种信道编码技术。
这里又涉及到一共新的名词,信道编码。信道编码是一门学科,代表人物有香农前辈、汉明码的发明人Hamming等,编码技术也是不胜枚举,曼切斯特编码、卷积码以及我们要说的8B/10B编码等等。信道编码又称之为线路编码,还可以称之为差错控制编码,其目的就是消除信号在传输过程中的干扰,让信号更干净,接收端能够准确的解析出来。所以8B/10B编码就是为实现上述目的所提供的一种编码方式。
从根本上了解8B/10B的目的和作用
3.1 高速串行通信需要解决的问题
高速串行通讯的实现有这样两个难点:
一是如何保证数据在传输中的质量,
二是接收端如何从01中将数据恢复出来。
当然,完成这项任务不是8B/10B编码一人就可以解决的,需要群策群力。
8B/10B编码的主要贡献有两个方面:
一是尽可能的保证串行数据流中的0和1平衡,
二是提供控制字符。
下面我们就从这两个方面来展开阐述。
保证0、1平衡,也就是0和1的个数差不多,再换句话说就是高电平和低电平的持续时间差不多。这是种说法很不专业哈,专用的说法叫直流平衡或者说DC平衡。为什么需要DC平衡呢,这和高速串行通讯物理实现方式有关。
对于高速信号的处理,可以使用直流耦合和交流耦合,对于高速串行通讯,若要实现远距离通讯或者光通讯,则只能使用交流耦合的方式。例如Xilinx的高速串行通讯模块GTP、GTX等,都有模拟前端AFE,就是电流模式高速输入差分缓冲器,如下图所示。
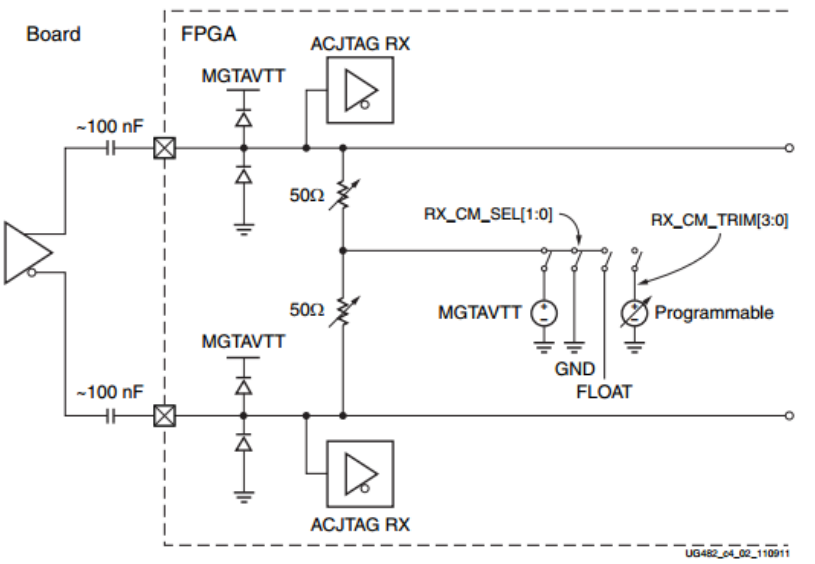
我们晓得电容特性是“隔直通交”,如果数据流中长时间没有电平翻转,那么必然会将其视为直流被阻断造成极性偏差,也就是电势差不满足高低电平的判断阈值,进而造成对接收电平信号的误判,进而导致接收数据出错,如下图所示。
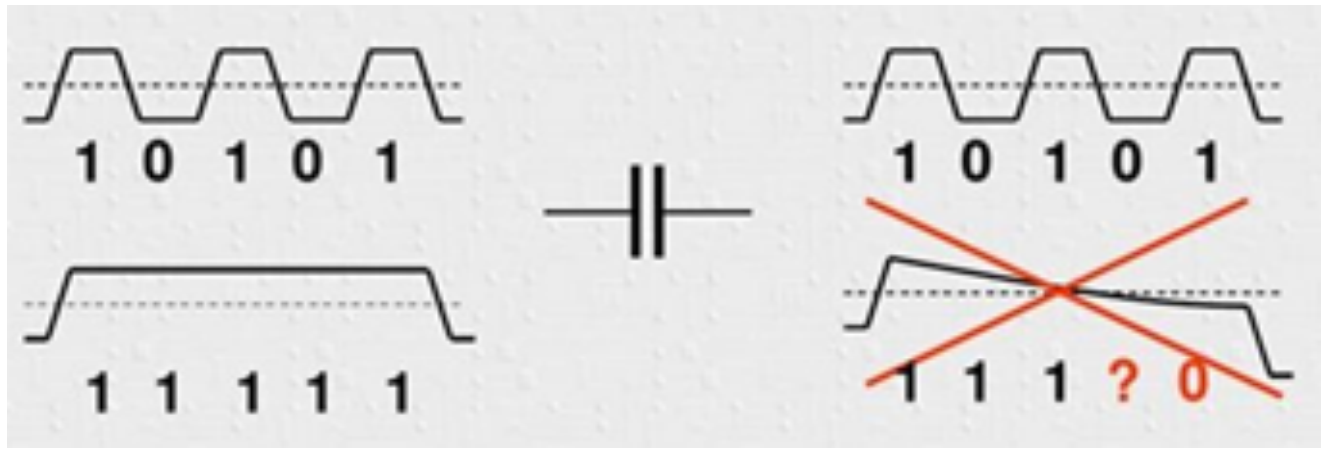
3.2 8B/10B编码提供的解决方案
看到这里有没有意识到8B/10B编码的目的了?如果是8Bit数据,必然会出现全是0全是1的情况,而如果出现连续5个“1”或5个“0”,则会导致DC不平衡。所以我们要对这8Bit数据进行编码,换一种方式,这种方式既能表示出8bit数所表示的数值,又能保证0和1不会长时间没有翻转,所以8B/10B编码应运而生。我们从10bit中挑出一些0和1差不多的来表示这256个数据,自然就能保证直流平衡。
这里,可能有个疑问,为什么要用10bit,而不是9bit或是11bit,因为这时在提高传输效率和保证传输质量间的最优解,可以体会下~
但凡接触串行通讯的朋友,相比都知道K码,用来实现据对齐到字节/字、通道绑定等功能。记得在学习初期,看到用户接口会在空闲时候发“BC”,当时我想破脑袋也没想明白一件事,接收端是如何区分K码和数据的。因为数据包里也有BC这个值呀?之所以产生这样的疑惑,是因为我简单的把8B/10B编码理解成给8bit数据填上2bit组成10bit数了。而实际不是填上,是从10bit这样1024个数里面挑出256个表示8bit数据,又从这1024个挑出12个来表示K码。所以8B/10B编码分为数据字符和控制字符两类,通过这两种类型数据的组合,我们就能从串行数据中将数据恢复出来。
另外,8B/10B编码还有很多好处,例如有助于时钟恢复,接收端需要根据我们发送的数据通过CDR把时钟恢复出来,只有提供足够的电平翻转,也能恢复出来也不至于PLL失锁。还能具有简单的纠错功能,如果检出10bit数不少标志规定编码,则表示边界未对其或数据存在问题。
8B/10B编码的实现机制
4.1 8B/10B的编码方式
本章来阐述下将8bit转换为10bit编码是如何实现的,转换的目的是保证DC平衡,所有用10bit表示8bit的原则也是尽可能的从1024个里面挑选出0和1差不多的,而且是01交替差不多的。但即便是1024个数据,0和1差不多且分布均匀的,也是少之又少,那我们怎么实现呢?
IBM公司的Al Widmer和PeterFranaszek为我们指定了编码准则,8B/10B的编码方案是将原始的8位数据分成2组,用y来表示高3位,用x来表示低5位.从高位到低位的8位数据依次命名为 H,G,F和 E,D,C,B,A.高3位 编 码 为4位,依次命名为f,g,h,j;低5位编码为6位,依次命名为a,b,c,d,e,i,如下图所示。则用“D”表示,所以数据字符就可以表示为Dx.y,例如十进制40,则表示D8.1。控制字符是用K表示,我们称之为K码,或叫“comma”,其表示方法和数据字符方法一样,即Kx.y,例如我们比较常见的K28.5、K28.7,控制码一共有12个。
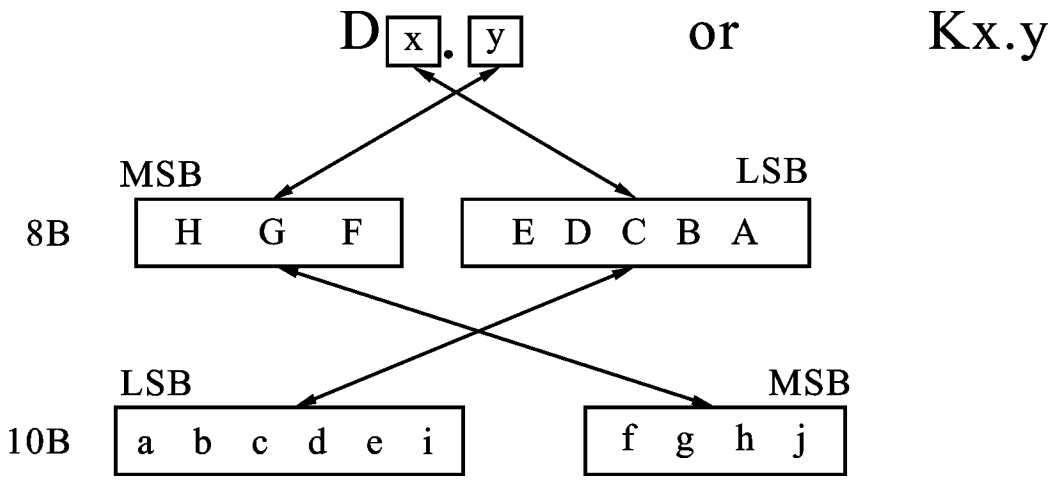
为什么要拆分5bit和3bit就能保证DC平衡呢?上文我们提到,如果出现连续5个1或0就会造成极性偏差,而串行数据只有0和1。所以我们不仅要保证本组编码后的10bit数没有连续这么多0或1,也要保住和上一组连在一起没有这么多0或1。采用这样“小数据段”的编码方式对硬件来讲更好实现,我们从6bit挑出不超过5个连续0和1的,从4bit数据挑出不超过3个连续0和1的,让它组合起来更有利于我们实现上述目的。如下这是3B/4B和5B/6B的编码表
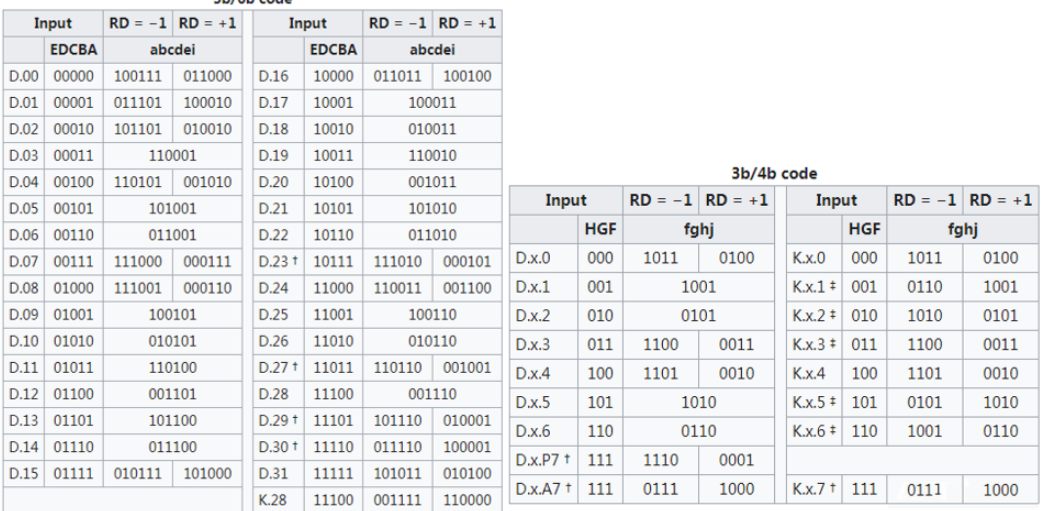
如下是12个控制码,这个就直接给出了

4.2 运行极性(RD)
这又引入了一个新的名词,叫做“RD”,全称running disparity,叫做运行不一致性,也就是我们上文提到的极性偏差。这个用来衡量编码数据的不平衡度,所谓的不平衡度就是编码数据中“1”的个数减去“0”的个数后的差值。
如果“1”的个数和“0”的个数相等,则称为完美平衡编码。如果编码后的4位数据块和6位数据块都是完美平衡代码,那么组合成的10位数据也是完美平衡代码,但这是不太可能的。
因为原始数据中的3bit有8中情况,编码后的4bit有16中情况,这16中平衡编码只有6种。原始数据种的5bit有32种情况,编码后的6bit有64种情况,其中平衡编码只有20种,所以必然会有不平衡状态。
编码后的10位数据代码的不平衡度值只可能是+2、0、-2。RD就是用来表示这个不平衡度的。据当前RD值合理选择编码数据,从而使编码后的10位数据的不平衡度为+2、0或-2。
4.3 编码的基本思路
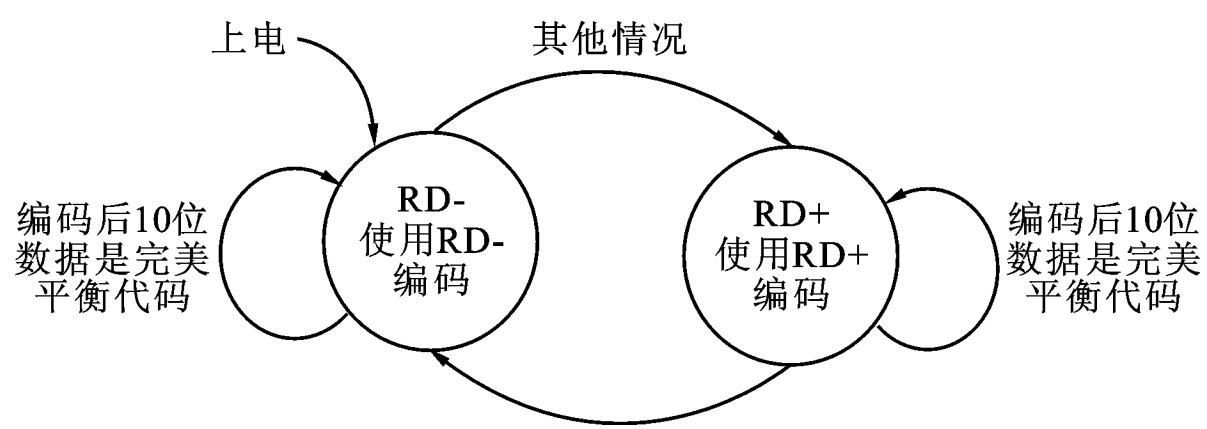
编码器在开始时一般设定RD值为负,即RD-,当编码一个8位数据时,如果编码后的10位数据是完美平衡代码,则RD值不变,如果不是完美平衡代码,则1的个数一定比0的个数多,将使RD值变为正。同样,如果RD值为正,若编码后的10位数据是完 美 平 衡 代 码,则RD值 依 然 为 正,否 则0的个数一定比1的个数多,使得 RD 值 变 为 负。RD状态如下图所示,描述了当前 RD值的计算方法。
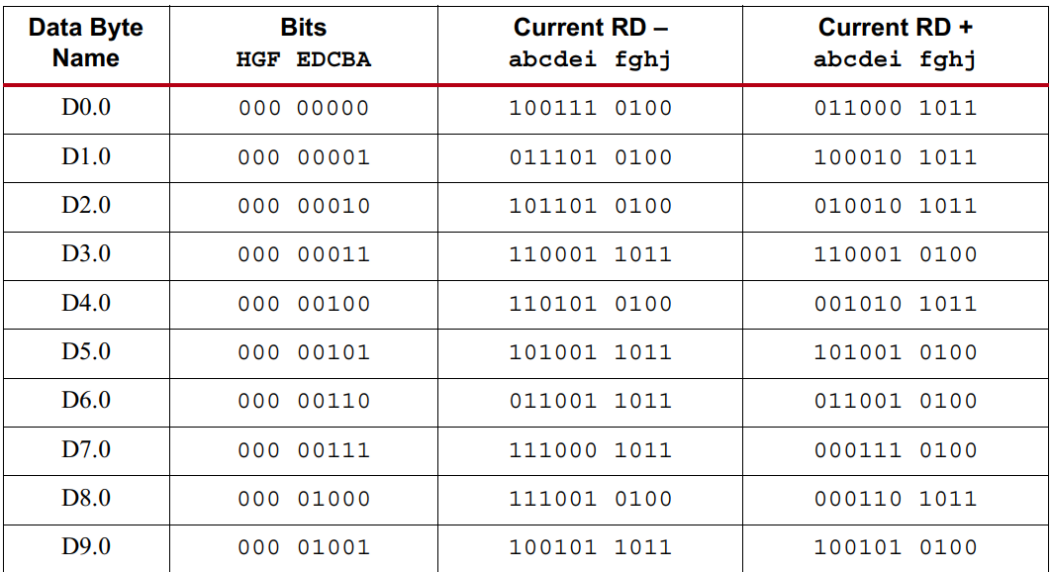
如下图是来自xilinx的8B/10B编码表。
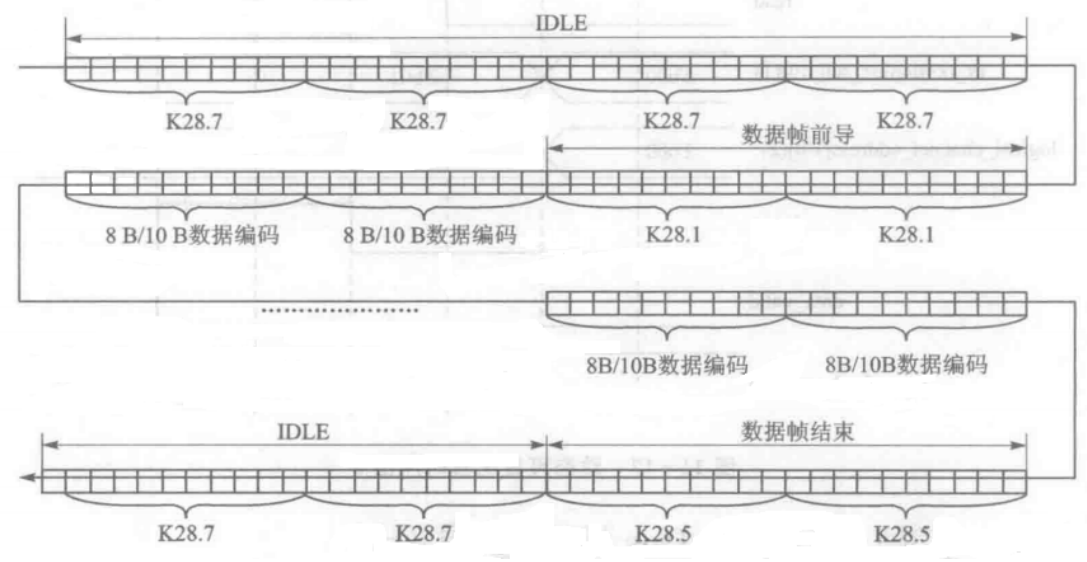
如下图所示,在数据流中不同的K码充当不同的角色,在数据恢复时,我们可以通过寻找K28.7来实现字节对齐,识别到K28.1准备接收数据,并在这不同阶段可以产生不同的状态信号。
快来扫描下方二维码关注公众号,领取站内所有相关资料,所有哦~
有建议、有需求、有疑问、联系我

